
Visual workflows are procedural programming in a costume
Why outcome specs beat node graphs in production

I’m always blown away looking at an agent described as an visual workflow. The boxes and lines expanding a collapsing are a joy to witness, and they scratch the same part of my brain that obsessed over tech trees in real-time strategy games. A system that answers questions is defined as dozens of lines and boxes that culminate in a summary in a markdown file.
By the time they’re done, the canvas looked like a circuit board designed by someone having a bad day. Forty-something nodes. Arrows crossing arrows.
You can see everything while simultaneously understanding almost nothing.
Boxes and arrows are just code in a costume
Here’s something that took me too long to realize about visual AI workflow builders. Strip away the drag-and-drop interface and what’s underneath is a control flow graph. Boxes are functions. Arrows are return values. Conditionals are if-statements. Retry loops are while-loops.
It’s procedural programming. The same paradigm as Python or TypeScript, just rendered as a diagram instead of text.
This matters because the visual layer doesn’t change the paradigm. It changes the representation. And the new representation is worse in almost every way that matters for production systems: harder to version control, harder to diff, harder to review, harder to refactor, harder to compose.
Over 25 years ago, L. Peter Deutsch watched a talk on visual programming and made an observation that became known as the Deutsch Limit: “The problem with visual programming is that you can’t have more than 50 visual primitives on the screen at the same time. How are you going to write an operating system?”
He was talking about general-purpose software. AI workflows hit that limit much faster. A moderately complex agent with tool calls, branching logic, evaluation steps, retry loops, and error handling blows past 50 nodes before you’ve handled the happy path. The visual representation that was supposed to make the system legible makes it less legible. The diagram becomes the thing you need a diagram to explain.
The shift nobody is talking about
The software industry has been through this exact transition before. More than once.
When you write SELECT * FROM orders WHERE total > 100, you don’t specify which index to use. You don’t tell the database whether to do a sequential scan or a hash join. You don’t manage memory allocation or disk I/O. You describe the result you want, and the query optimizer — decades of engineering condensed into a planner — figures out the execution path. This is what makes SQL so durable. The same query runs on SQLite and on a distributed Snowflake cluster. The what stays the same. The how adapts to the context.
Terraform did the same thing for infrastructure. Before Terraform, deploying infrastructure meant writing imperative scripts: create this server, configure this load balancer, attach this security group, in this order, and hope nothing fails halfway through. Terraform replaced all of that with a declaration: “I want 5 instances behind a load balancer in us-east-1.” The system reads your desired state, compares it to reality, and converges.
Kubernetes did it for container orchestration. “I want 3 replicas of this service, always.” Not “launch a container, check if it’s healthy, restart it if it crashes, scale up if load increases.” You declare the outcome. The system maintains it.
Every one of these transitions followed the same arc: procedural tools that worked fine at small scale became unmanageable as complexity grew. Declarative tools replaced them not by doing the same thing with a nicer interface, but by operating at a different level of abstraction.
What’s the word for the version of this shift in AI evaluation? I think it’s happening right now, and most people are building on the wrong side of it.
The plumbing problem
Now look at how visual AI workflow tools handle evaluation. Take a concrete example: Vellum’s recommended architecture for a RAG evaluation loop. You wire a Prompt Node to a Guardrail Node that runs an evaluation metric at runtime — say, Ragas Faithfulness. If the score is below your threshold, you route the failure path through a Conditional Node back to the Prompt Node for another attempt. You need a Templating Node to track the Prompt Node’s execution counter so the loop doesn’t run forever. You add a second Conditional branch for when retries are exhausted. You add a Try adornment on the Prompt Node to expose an error output for non-deterministic failures. You wire the success path through a Merge Node to a Final Output Node.
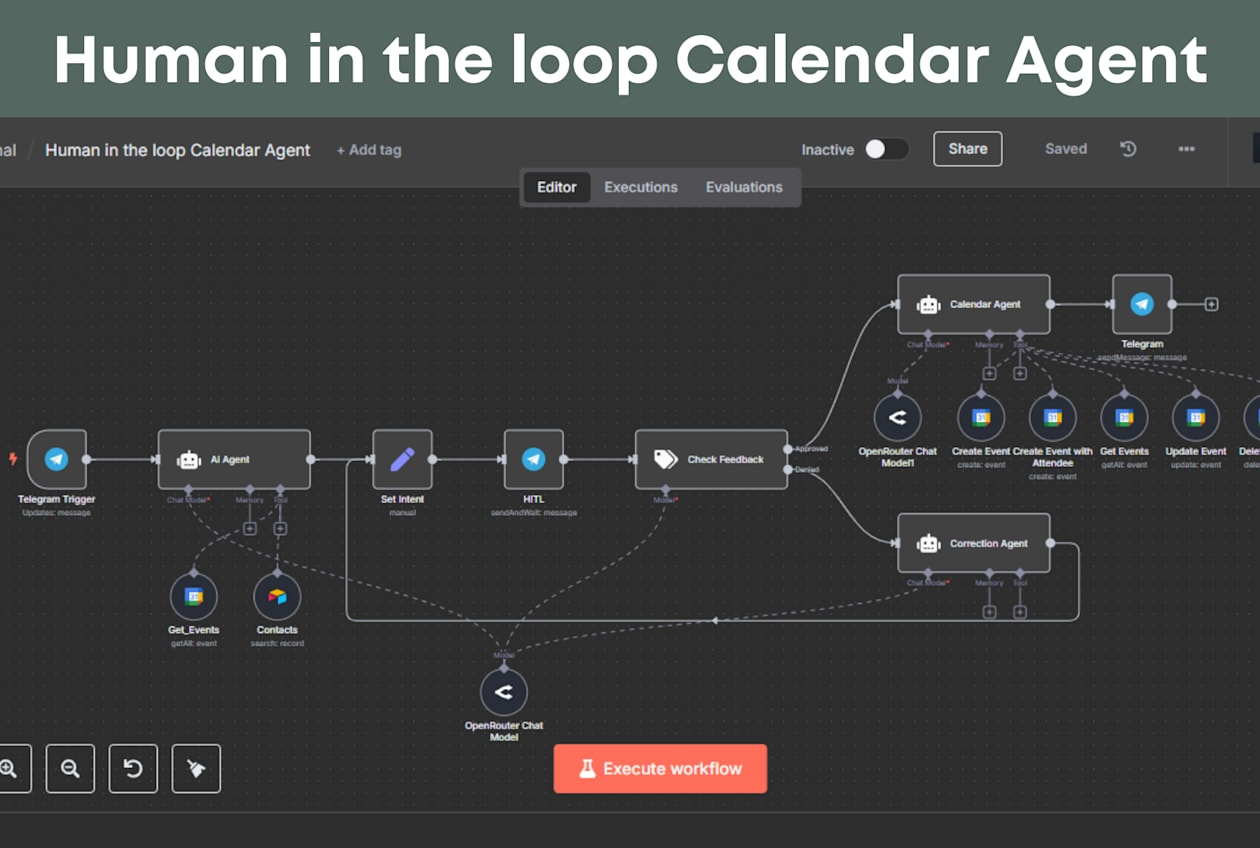
That’s seven node types — Prompt, Guardrail, Conditional, Templating, Merge, Final Output, and Error — plus adornments, for a single evaluate-and-retry loop on a single output. And this is the recommended pattern. If you want to evaluate multiple dimensions (factual accuracy and tone and completeness), each dimension needs its own Guardrail Node, its own branch, its own merge. The graph doesn’t grow linearly. It grows combinatorially.
Other tools have the same problem. On one community forum, a user asked how to implement a conditional while loop — a basic evaluation retry. The answer: chain a Loop node to an IF node to a Wait node, wire the true path back to the loop, and “be very careful on trigger infinite loop.” That’s the level of primitive you’re working with.
You’ve specified the procedure, step by excruciating step. If you want to change the evaluation criteria, you’re re-wiring nodes. If you want to add a rubric dimension, you’re adding boxes and arrows. If you want to change the retry strategy, you’re restructuring the graph.
That’s not evaluation. That’s plumbing. And just like imperative deployment scripts before Terraform, the plumbing obscures the thing that actually matters: what does “good” look like?
What declarative evaluation looks like
Here’s an evaluation specification from a Jetty runbook I use in production:
The output must contain these 7 files. Each file must pass schema validation. The narrative summary must score 7+ against these rubric dimensions: factual accuracy, clinical relevance, actionable recommendations, appropriate tone. If it scores below 7, identify the weakest dimension, revise, and re-evaluate. Maximum 3 iterations.
That’s the entire evaluation logic. Twelve lines of markdown. No boxes. No arrows. No retry-loop wiring. No conditional branches.
The agent reads this and does what a competent human would: produces the output, checks it against the criteria, fixes what’s weak, and iterates until the bar is met or the budget is exhausted. The what is specified precisely. The how is left to the executor.
Compare this to the visual workflow version of the same logic. I counted the nodes in a visual implementation of this evaluation loop: 23 nodes, 31 connections, and I still hadn’t handled the case where schema validation fails on a different file than the one the rubric scored lowest.
The declarative version is not just shorter. It’s a different kind of thing. It’s a specification, not a procedure. And specifications have properties that procedures don’t.
Specifications compose. Procedures tangle.
Want to add a new rubric dimension to a declarative evaluation? Add a line. Want to change the iteration limit? Change a number. Want to swap the underlying model? Change a parameter. Want to apply the same evaluation criteria to a different pipeline? Copy the specification and change the input path.
Try any of these in a visual workflow builder. Adding a rubric dimension means adding evaluation nodes, re-wiring branches, and testing the new graph. Changing the iteration limit means restructuring the retry loop. Swapping the model might mean replacing nodes that have different input/output schemas. Applying the evaluation to a different pipeline means... rebuilding the workflow from scratch, because the node graph doesn’t separate the evaluation logic from the execution context.
This is why nobody writes Terraform in a drag-and-drop GUI. The text representation is more powerful, not less. Not because text is inherently better than graphics — but because declarative text separates what from how in a way that visual procedures cannot.
SQL views compose because each one is a self-contained query with declared dependencies. Terraform modules compose because each one is a self-contained state declaration. Kubernetes manifests compose because each one is a self-contained desired-state spec. Evaluation specifications compose because each one is a self-contained quality bar.
Visual workflow nodes don’t compose. They connect. And connections are fragile. Move one node and three arrows break.
The version control problem is fatal
Here’s the tell that the visual approach has a fundamental problem: every serious visual workflow tool eventually builds a text-based SDK.
One platform launched a Workflows SDK with a CLI that does “bi-directional syncing” between the canvas and code. Another open-sourced a text format alongside its visual editor. A third supports workflow-as-code. They all end up in the same place: acknowledging that the visual representation isn’t the source of truth. It’s a rendering of the source of truth. And the source of truth is text.
The reason is version control. Visual workflows serialize to JSON blobs — hundreds or thousands of lines of auto-generated coordinates, node IDs, and connection metadata. You cannot meaningfully diff them. You cannot code review them. You cannot grep for the line where the evaluation threshold is defined. When two people edit the same workflow, you cannot merge their changes.
The right abstraction to visualize is outcomes: what does the evaluation measure, what’s the quality bar, and what are the iteration bounds. The procedure is an implementation detail the system should handle, the same way a SQL query optimizer handles join ordering.
Promptfoo seems to get this. Its evaluation framework uses declarative YAML — you specify assertions (string matching, LLM-as-judge rubrics, schema validation) and it handles execution. It’s closer to a testing DSL than a visual workflow. That’s the direction the ecosystem should be heading.
The parallel to testing
This connects to something I’ve been writing about for a while. CI/CD worked because it made every change small, testable, and reviewable. The CI loop depends on artifacts that diff cleanly: code in text files, tests in text files, configuration in text files.
Visual workflow builders fight this at every level. Changes don’t diff. Reviews are “look at my screen and tell me if this graph looks right.” Rollbacks mean “restore the previous version of an opaque JSON blob.” The very properties that made CI/CD transformative — small changes, clean diffs, automated testing, code review — are the ones that visual workflows undermine.
Declarative evaluation aligns with CI because it produces the same kind of artifacts. A runbook is a text file. It diffs. It reviews. It lives in a PR. When you change the evaluation criteria, the diff shows exactly what changed and nothing else. When you add a rubric dimension, the reviewer can assess whether it makes sense without understanding the execution plumbing.
This is the same advantage Terraform has over bash deployment scripts, and SQL has over hand-rolled data-processing code. The artifact is reviewable because it describes intent, not mechanism.
Procedural visual tools will always address an important segment of the market. Some tasks genuinely need step-by-step control — data plumbing, API integrations, deterministic pipelines where every step is known in advance. That’s real, and visual builders serve it well.
But most AI tasks aren’t like that. Most AI tasks are measured by their outcome, not by whether you followed the right steps. Did the summary capture the key points? Did the generated image match the brand guidelines? Did the evaluation catch the regression? These are outcome specifications, not procedure specifications. It’s the difference between listing the ingredients for a dish and prescribing exactly which store to visit, which aisle to walk down, and which hand to reach with.
The most sophisticated agent orchestration I’ve seen isn’t a graph. It’s a markdown file with a rubric, an output manifest, and a verification script. It version-controls perfectly. It diffs in a PR. It’s human-readable and machine-executable. It composes by copy-paste and edit, the way SQL views do.
The format sounds primitive, but so did SELECT * FROM when compared to a visual query builder. The power was never in the interface. It was in the abstraction.
Where visual workflows make sense
It’s not all bad! There are some cases where a visual workflow tool can be a huge productivity gain. MaxMSP is a fantastic example of how a visual workflow tool can actually increase visibility into what’s going on under the hood. Tools like After Effects, Blender and many shader mapping interfaces for game designers are also good examples. But I think in each of these instances, an expert has to be prepared to learn and adopt the visual programming environment wholesale—and they still face an upper bound in terms of how much complexity any of these visualizations can communicate to humans.