
Verifiable Agents Engender Trust in Systems
Turning confident guesses into measurable claims

A customer asked me a sharp question on a call last week. Why generate a batch of possible solutions and prune down to the good one? Can’t you spend that same compute getting the answer right the first time? Generating ten and throwing away nine looks wasteful. One careful pass looks like the disciplined engineering choice, the way you’d want a senior person to work.
There’s some math we could go into about increasing variance of outcomes, which we can get into, but fundamentally this post is about trust.
We trust colleagues who tell us when they are wrong and then fix their mistakes. Think about who you actually rely on at work. It isn’t the person whose code never has bugs, because that person doesn’t exist; it’s the person who says “I broke the build, I’m on it” before you have to go find them. That honesty is only possible because there is a shared standard both of you can check against, whether the test suite went red or the customer complained or the number moved. Take away the standard and you get opaque responses like “looks great” every time, and you end up with a new job: quietly verifying everything yourself.

An agent with a shelf full of skills and no evaluation is that colleague. I wrote a while back about watching an agent run a six-step pipeline, skip two of the steps, and declare the whole thing complete with the confidence of someone who had finished. Because the agent didn’t have criteria for when it should terminate, it had no way of determining whether it had completed the workflow correctly.
Having some grounding in an agentic workflow is the precondition to building trust, and the evaluations are a mirror. Without a reflective step, the agent cannot be honestly wrong, which means it is something you have to babysit forever.
The idea that countervailing objectives keeps coming: whether it’s a primal/dual Lagrange formulation, generators and discriminators in GANs, exploration and exploitation in bandits, or an actor/critic in RL, the idea that you need a source of variance and a means to control that variance keeps recurring in AI.
My belief is that having these two signals for learning ends up breaking up the problem in a way that reduces the overall predictive power, and ultimately computing resources, required to get to a good solution.
For most useful work, checking whether an answer is good is far easier than producing a good answer from nothing, the way verifying a filled-in Sudoku takes a glance while solving the blank one takes concerted effort. Generation got cheap and verification didn’t keep pace, and that gap is the whole reason generate-and-prune beats the single careful shot. When AlphaCode competed in programming contests, it didn’t reason its way to one elegant program. It generated something close to a million candidates per problem and then filtered them down, because the generator on its own was mediocre and the generator plus a verifier was competitive with humans.
Explore then Exploit
After a few years of training models before I built developer tools, the thing that finally made this click for me was a framing that comes from reinforcement learning. You cannot exploit a solution you have never generated. A single careful pass is pure exploitation of whatever the model already thinks is most likely, so when that most-likely answer is wrong, no amount of extra compute poured down the same path finds the better answer sitting at lower probability. You have to explore before you can exploit, which is what generating many candidates is for. The verifier is how you cash in on what the exploration turned up.
Connecting Verifiers to Skills
Which brings us to skills, because the industry has fallen in love with the wrong half.
A skill is a generator. A CLAUDE.md rule or a tuned markdown guide shifts the distribution you sample from toward better output, and that is genuinely useful work. But a skill is not a verifier, and stacking more of them never turns it into one. The agent gets no signal from them, and neither do you: if all you have is skills, you cannot tell whether last month’s changes left the system better or worse, which is the whack-a-mole loop where every fix feels like progress and nothing compounds. An evaluation closes that gap because it is the one artifact that can say “this run failed, here is the check it failed”.
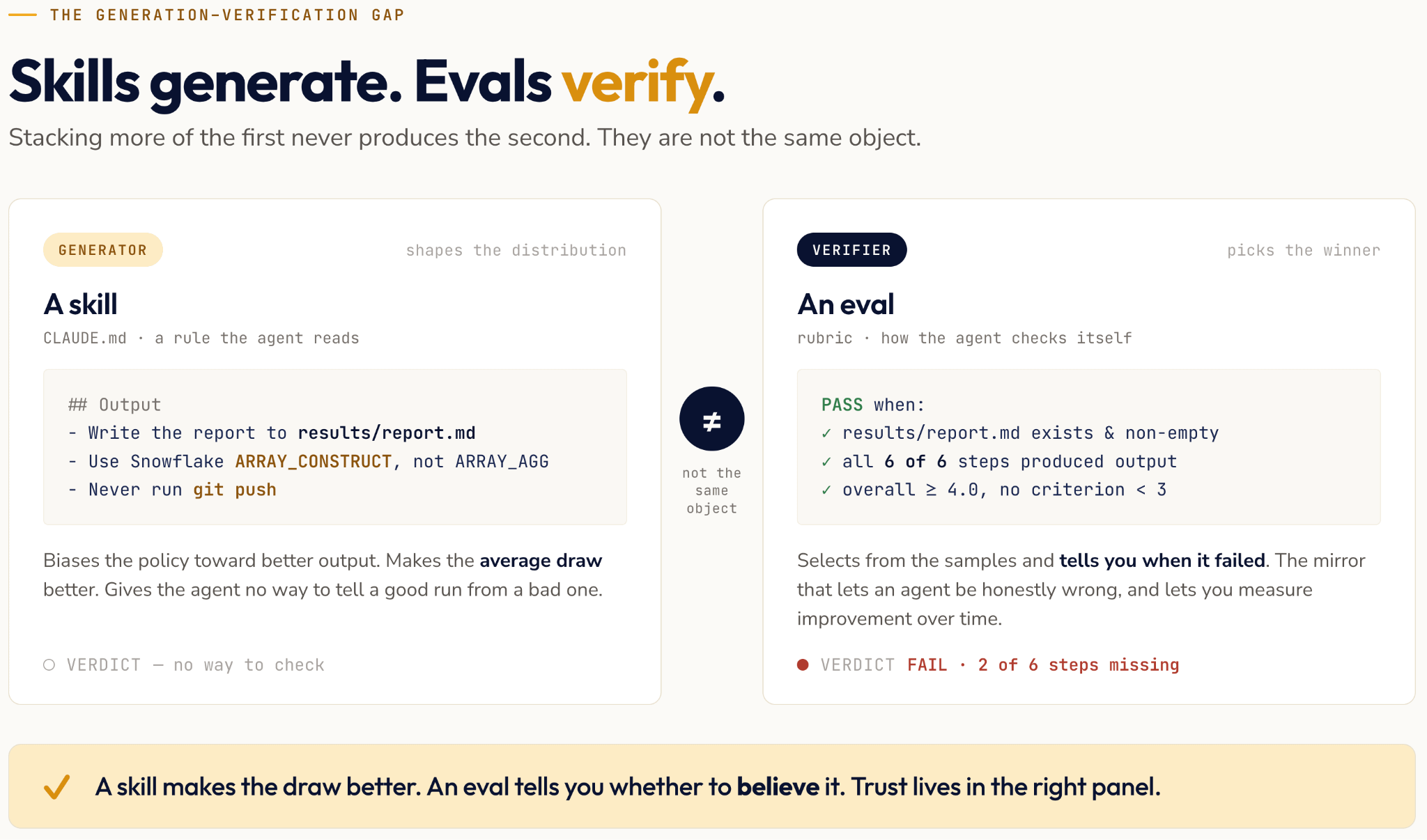
There is a quieter cost to the skills-only approach, and it surfaces the day you try to leave. Every rule you add is written against one harness, so it lives in that tool’s config and assumes that tool’s defaults, and when you swap your agent for a different one next year the rules don’t come with you. An evaluation has no such problem, because “here is what good output looks like and here is how to check it” is a statement about your problem rather than about your tooling.
The Harness is Disposable
The generator is shaped like the harness and is disposable; the verifier is shaped like the work and outlives every harness you run it through. If you are going to invest somewhere durable, invest there. None of this means generation doesn’t matter. A better generator paired with a good verifier beats a worse one every time, and skills are exactly how you get the better generator. The point is narrower, and easy to miss while everyone is shipping skill libraries: the thing you are actually buying when you build generate-and-verify isn’t a marginally better answer, it is a system that can tell you when it failed. That property is the precondition for trust, and trust is the only thing that lets you stop checking the work by hand.