
Stop Building Against Gold Datasets
Why frozen benchmarks can't measure living systems

In grad school, the first thing you learn in any machine learning course is to find a good dataset. MNIST for vision. SQuAD for reading comprehension. GLUE for language understanding. These are “gold datasets”: carefully curated, cleanly labeled, academically blessed. They exist so you can focus on the algorithm and avoid getting tangled in messy data problems.
This makes sense in a classroom. It makes no sense in production. Gold datasets teach you to think about data as something you obtain once, hold still, and measure against. That assumption breaks the moment your system touches real users.
The dream of separating code from data
Software engineering spent decades pulling code and data apart. FORTRAN had DATA statements that hardcoded values directly into the program. COBOL formalized the separation with its DATA DIVISION. From there, the trajectory was consistent: relational databases, config files, environment variables. The Twelve-Factor App made it doctrine: “strict separation of config from code.”

Then foundation models arrived and broke the assumption entirely.
An LLM’s behavior is inseparable from the data it was trained on, the examples in its prompt, the documents retrieved by its RAG pipeline. Change any of these and you change what the system does. The data is the code. We’ve come full circle, back to FORTRAN’s DATA block, except now the data block is a few billion parameters and a prompt template that gets rewritten every sprint.
What gold datasets actually measure
Here’s the uncomfortable truth about the benchmarks the ML community treats as ground truth: they’re often wrong.
A 2024 analysis of MMLU, the benchmark most commonly cited when comparing LLM capabilities, found that 6.5% of questions contain errors. In the virology subset, 57% of questions had problems: wrong answers, ambiguous phrasing, missing context. The maximum achievable score isn’t 100%, and nobody agrees on what it actually is.
When researchers added adversarial distractor sentences to SQuAD reading comprehension passages, model accuracy dropped from 75% to 36%. With ungrammatical adversarial sequences, it fell to 7%. The models weren’t reading. They were pattern-matching against a dataset they’d learned to game.
The deeper problem is Goodhart’s Law: when a measure becomes a target, it ceases to be a good measure. Models that score 87% on HumanEval for code generation drop to around 30% accuracy on real-world codebases with cross-file dependencies, internal frameworks, and legacy patterns. The benchmark says the model is excellent. Production says otherwise.
The team tension nobody talks about
I watched this dynamic play out repeatedly before and while building Jetty.
The data science team builds a pipeline against a clean CSV from six months ago. The data is tidy. The labels are consistent. The model performs beautifully. Meanwhile, the developer integrating it into production knows that real inputs look nothing like that CSV. Fields are missing. Formats are inconsistent. Users submit things nobody anticipated.
Both sides are acting rationally. The data scientist needs controlled conditions to iterate on the model. The developer needs to ship something that works for actual users. The gold dataset becomes a shared fiction: everyone references it, nobody fully trusts it, and the gap between lab performance and production reality widens with every sprint.
This isn’t a communication problem. It’s a structural one. Gold datasets encode the assumption that you can fix your data, fix your model, and measure once. AI systems break that assumption. The data distributions shift, the models get updated, the retrieval systems change, the code evolves. A frozen dataset tells you how the system performed against a historical snapshot, not how it performs right now.
Data collection is not a phase
The alternative isn’t “better gold datasets.” It’s abandoning the concept entirely and treating data collection as a continuous, live process wired into production.
Shreya Shankar’s research put it bluntly: “We have no idea how models will behave in production until production.” Her interviews with ML engineers across chatbots, autonomous vehicles, and finance found a consistent pattern: the teams that succeed close the loop fastest, continually cycling between data collection, experimentation, staged evaluation, and monitoring.
This is the data flywheel. Your product generates data. You analyze that data to find where the system fails. You fold those failures back into your evaluation sets and training data. Each cycle makes the next one more valuable, because you’re measuring against reality, not a proxy for it.
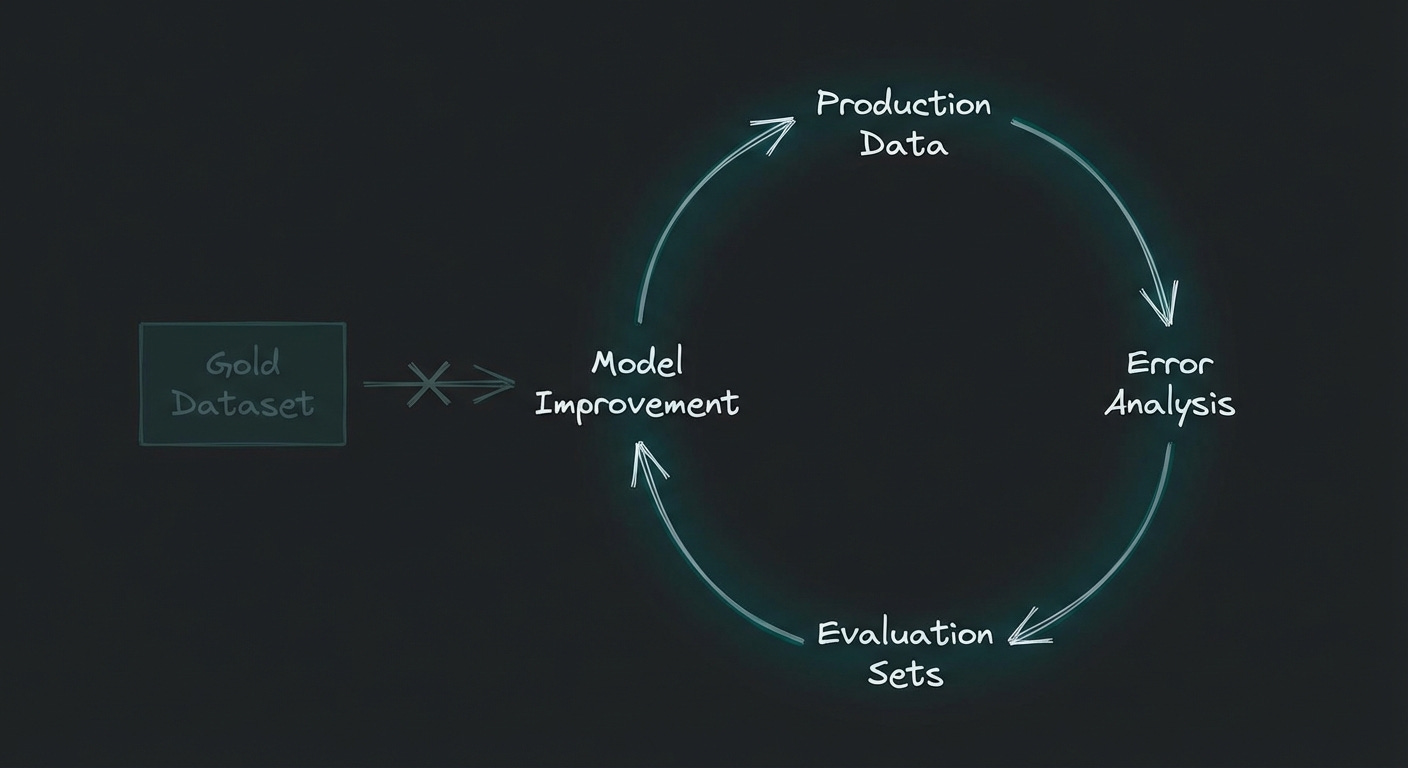
Hamel Husain makes a practical version of this argument: start with error analysis. Look at your production data. Categorize failures. Write evals that catch the failures you’ve actually seen. He warns against chasing high pass rates. If you’re at 100%, you’re not stress-testing your system. A 70% on meaningful, production-derived evals tells you more than 95% on a benchmark that doesn’t reflect your users.
But what about PII?
The main objection I hear is privacy. “We can’t use production data — it contains PII. Regulatory compliance makes this impossible.”
This is real. But it’s not a reason to default to stale snapshots. It’s a reason to invest in the infrastructure that makes live data collection safe. Anonymization pipelines. Differential privacy. Synthetic data generation from production distributions. None of this is trivial, but the alternative is worse. You’re not protecting users by ignoring how your system behaves in the wild. You’re deferring the risk.
The privacy experts I’ve worked with are far more worried about uninstrumented systems that can’t detect when they fail on a vulnerable population than about well-designed systems that safely collect production signals. Avoiding production data entirely isn’t caution. It’s the opposite of it.
The first step
If your team is still building against a gold dataset, here’s where to start: pick one pipeline that matters, instrument it to capture real inputs and outputs, and run your existing evals against production data instead of your test set. You will be surprised by the gap. Production is weirder, messier, and more varied than any curated dataset can capture. That gap is the information you need. Gold datasets hide it. Live data reveals it.
The question isn’t whether your gold dataset is good enough. It’s whether you can afford to keep pretending that a frozen snapshot tells you anything useful about a system that never stops changing.