
Runbooks: what agents need to hill-climb
The Missing Layer Between “Call This API” and “Accomplish This Outcome”

Last month I watched an agent run a six-step evaluation pipeline. It called the right APIs. It generated SQL that was mostly correct. It even caught a schema error and fixed it on the second try. Then it wrote a summary, declared the task complete, and stopped.
It had skipped two of the six steps entirely. The output directory was missing three of five required files. The summary confidently described results from steps that never ran.
This is the failure mode nobody talks about. Not “the agent can’t do the task.” The agent can do the task. It just doesn’t finish it. It encounters an error on step four, routes around it, produces whatever it can, and wraps up with the confidence of someone who definitely completed all the work.
If you’ve built anything non-trivial with coding agents, you’ve seen this. The agent is capable but unreliable. It needs something between a one-line instruction and a shell script. It needs what I’ve started calling a runbook.
Skills, workflows, and the gap between them
Most agent tooling falls into two buckets.
Skills are single-turn instructions. “Here’s how to call the Jetty API.” “Here’s how to query Snowflake.” They’re reference cards. Useful, but they don’t handle multi-step processes where the output of step three determines what you do in step four.
Workflows are fixed pipelines. Step A feeds step B feeds step C. They’re deterministic, which is their strength and their limitation. When the task requires judgment — “is this SQL output correct?” or “does this image match the brand guidelines?” — a workflow can’t adapt.
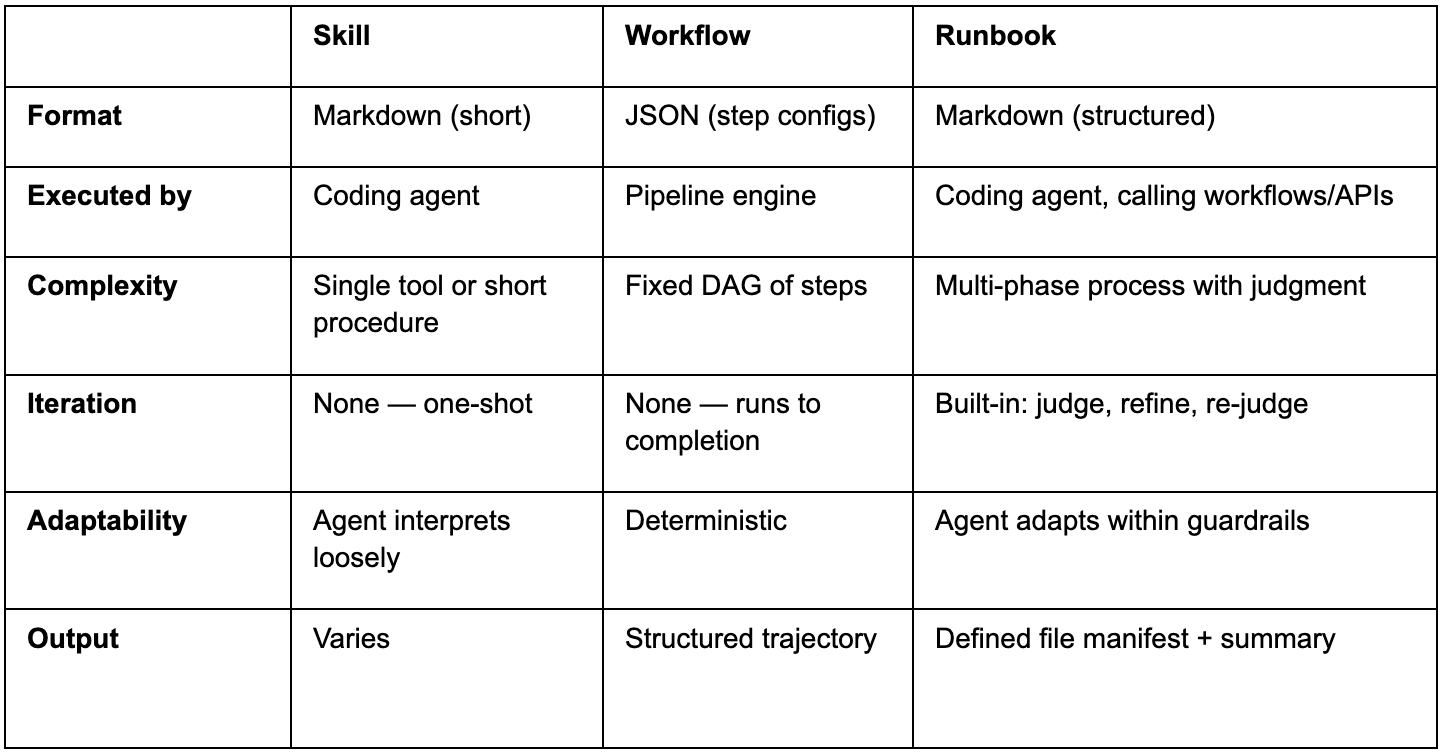
That’s not a skill. It’s not a workflow. It’s a process that requires both execution and judgment, with the ability to recover when things go wrong.
What a runbook actually is
A runbook is a structured markdown document that tells an agent how to accomplish an outcome. Not a procedure to follow blindly. An outcome to achieve, with enough guidance to get there.
The distinction matters. A shell script says “run these commands in this order.” A runbook says “here’s what must be true when you’re done, here’s how to evaluate whether you’re there, and here’s what to do when you’re not.”
The critical sections, in order:
An objective. Two to five sentences that answer: what am I doing, what am I producing, and for whom? The agent should be able to read this in ten seconds and orient.
An output manifest. The exact files that must exist when the task is complete. This is deliberately aggressive:
You MUST write all of the following files. The task is NOT complete until every file exists and is non-empty. No exceptions.
That tone exists for a reason. Agents are polite. They want to wrap up gracefully even when they haven’t finished. The manifest is a forcing function against the premature completion problem I described at the top.
Evaluation criteria. How the agent knows whether its output is good enough. This is the section that separates a runbook from a to-do list.
An iteration loop. What to do when evaluation fails. Try again, but differently, and with a cap on how many times.
A final checklist with a verification script. A bash script that checks every output file exists and is non-empty, plus a prose checklist the agent walks through before declaring completion.
That last part — the script — is the only reliable way to prevent the failure I opened with. Without it, the agent will skip steps and tell you everything went great.
The hill-climbing loop

Every runbook contains at least one judge-refine-rejudge cycle. The agent produces output, evaluates it against criteria, and iterates if it falls short.
This is the same hill-climbing pattern that works in optimization: define a quality bar, measure against it, improve the weakest dimension, measure again. The runbook just makes it explicit and bounded.
Bounded is the key word. Without a cap, agents will iterate forever or give up after one attempt. Three rounds is the sweet spot I’ve landed on. Enough to converge on most issues, not enough to burn through your API budget on a lost cause. The runbook specifies what happens when you hit the ceiling: keep the best attempt, flag for human review, or both.
Two evaluation patterns cover almost everything:
Programmatic validation for structured output. Does the JSON schema-validate? Does the SQL execute? Do the tests pass? Error messages are specific and actionable, so the agent converges in one or two rounds.
Rubric-based judgment for creative or complex output. Score against multiple criteria on a 1-5 scale, with a pass threshold (like “overall >= 4.0, no criterion below 3”). The agent identifies the weakest criterion and makes targeted improvements. A “Common Fixes” table maps failures to concrete actions — this is where you encode the domain expertise that prevents the agent from thrashing.
The pattern you choose depends on the output. Don’t rubric-score a JSON file. Don’t schema-validate a marketing graphic.
The new-hire test
Here’s the mental model I use. A runbook is what you’d write for a competent new hire who needs to run your pipeline while you’re on vacation.
You wouldn’t write a shell script. Too brittle — the first unexpected error kills it. You wouldn’t just say “figure it out.” Too vague — they’ll make assumptions you’d never make. You’d write something in between: the process with enough detail to recover from common failures and enough latitude to adapt when something unexpected happens.
You’d include the API calls they’ll need, with examples. You’d describe what good output looks like. You’d list the things that commonly go wrong and how to fix them. You’d tell them exactly which files to produce and how to verify they’re correct before calling it done.
That’s a runbook. The agent is the new hire. The markdown is the document you leave behind.
Tips are earned, not invented
The last section of every runbook is “Tips.” These aren’t generic best practices. They’re hard-won operational knowledge from watching agents actually run the process and fail.
Things like: “Langfuse auth uses HTTP Basic, not Bearer — agents default to Bearer and get a confusing 401.” Or: “Snowflake function names differ from Spark. If the SQL references ARRAY_AGG, the agent will need to use ARRAY_CONSTRUCT instead.”
These accumulate over time. Each failed run teaches you something the next version of the runbook should encode. The tips section is the runbook’s institutional memory — the things you’d tell the new hire over coffee that aren’t in any documentation.
Try this now
This isn’t theoretical. The Jetty agent-skill ships with tooling for running and validating runbooks.
validate-runbook.sh checks structural completeness without executing anything. It tells you whether your runbook has all the required sections, whether your template variables are declared, whether your evaluation criteria exist. Think of it as a linter for operational documents.
run-runbook.sh reads a parameters JSON, injects template variables, and invokes the agent with the runbook as its instruction set. It supports a --dry-run mode where the agent reads the runbook and produces an execution plan without making any API calls — useful when the pipeline involves expensive operations like image generation or database queries.
The barrier to entry is: write a markdown file with the sections above, validate it, and run it. If you’ve already got a process you run manually or a pipeline that an agent keeps botching, that’s your first runbook.
The contrarian bet
There’s an irony here. While the industry is building increasingly complex agent frameworks — tool chains, memory systems, multi-agent orchestration, graph-based planners — the most reliable guidance mechanism I’ve found is a well-structured markdown file with a verification script at the bottom.
Markdown is plain text. It works with every agent. It’s version-controlled. It’s diffable. It’s readable by humans and machines. It doesn’t require a runtime, a framework, or a dependency. You can review it in a PR.
The sophistication isn’t in the format. It’s in what the document encodes: clear evaluation criteria, bounded iteration, concrete output requirements, and operational knowledge from real failures. That’s what makes an agent reliable. Not the orchestration layer. The quality of the instructions.
I suspect this will seem obvious in retrospect. The same way “just write tests” seems obvious now but was a hard sell in 2005. The discipline is in writing down what “done” looks like before you start — and giving the agent a way to check its own work.
What’s less obvious is where the ceiling is. How complex can the task be before a single markdown file stops being sufficient? I don’t know yet. But the tasks I’ve thrown at runbooks — evaluation pipelines, data ingestion, brand compliance checking, regression testing — keep working. The format scales further than I expected.
The question I’m sitting with: if the best agent orchestration is a document with a rubric and a bash script, what does that tell us about where the real leverage is in AI systems?
Great piece, Jonathan. I like the premature completion diagnosis. And the output manifest with bash verification is an interesting response. I want to push on a few assumptions in the piece:
Workflows are not fixed deterministic pipelines. A workflow defines required steps with verification at each transition. Within those steps, judgment happens freely. What determines advancement from step 1 to step 2 can itself involve judgment: did the output meet a quality bar, does this case require escalation. That's sequenced accountability with gates, not rigidity. The runbook's end-of-run verification checks final state. It cannot enforce that step A completed before step B consumed its output, or that evaluation at step 3 occurred before step 4 ran. A workflow enforces ordering and gate-passing as structural properties of execution. A runbook encodes them as instructions the agent may or may not follow.
While it's true that the bash verification script is not advisory in the way prose instructions are (deterministic check that validates file existence and schema correctness produces a hard pass/fail the agent cannot rationalize away), the question is what acts on the measurement. If the agent reads the result and decides what to do, you have a hard measurement inside an advisory enforcement loop. If the harness blocks delivery on failure, that's genuine enforcement. The remaining advisory surface is ordering and intermediate evaluation, which stay as prose the agent interprets. So the architecture is a hybrid: hard verification at the boundary, advisory governance over trajectory.
That hybrid is well-suited to some kinds of work and less to others. Plenty of real institutional processes already use end-of-sequence verification: check completeness and quality at the end, don't prescribe intermediate ordering. But step-gated governance emerged as an institutional response to work with specific properties: known failure modes at transitions, volume that justified the overhead, auditability requirements demanding evidence of sequenced accountability. Organizations built procedural governance because certain work punished you for skipping steps in ways final-state checks couldn't catch. Even with identical agent capability, different work will demand different governance paradigms based on criticality, failure modes, and audit needs. Runbooks fit the first category well. Whether the form stretches to the second, or whether you end up reinventing orchestration, is the open question.
That raises the following question: what distinguishes a runbook from an orchestrated agent loop in LangGraph or Temporal? Built as an orchestrated graph, the same steps and evaluation criteria would get structural enforcement of ordering, separation of executor and evaluator, and deterministic gate logic. The runbook's advantage is portability: markdown works everywhere, no runtime dependency. The tradeoff is that trajectory governance stays advisory. The composable design is probably runbooks for judgment-heavy work where flexibility matters and final-state verification is sufficient, orchestration for work where enforcement has to be structural over the full execution path.