
My Backend is 442 Lines of Markdown
We shipped a web app whose entire backend is a structured document

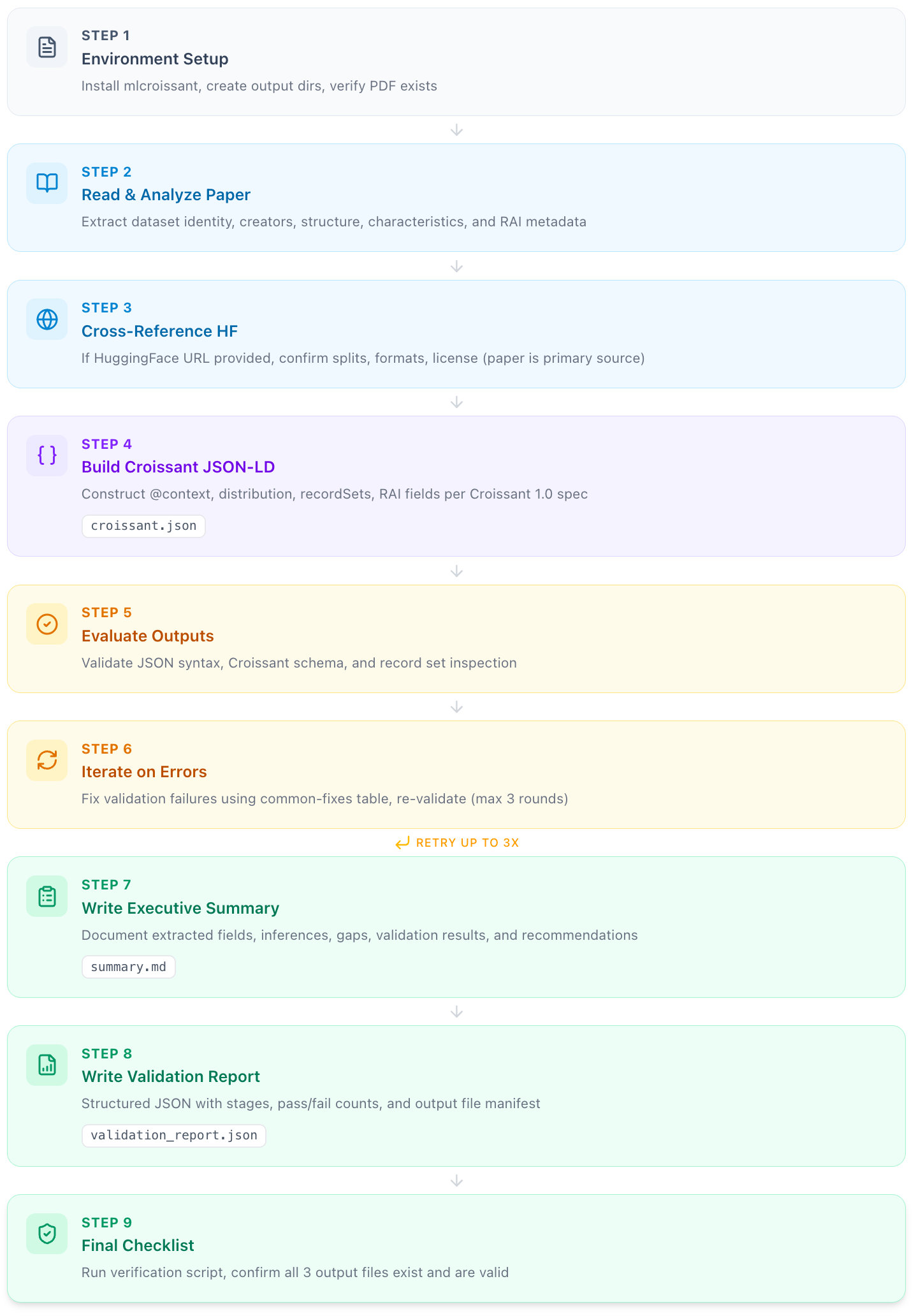
A few weeks ago we shipped mlcroissant.jetty.bot — paste in a URL to an academic dataset paper, and get back an MLCommons Croissant metadata file. It extracts the dataset’s provenance, fields, and license, then packages everything as machine-readable JSON-LD. The backend is a 442-line markdown file. No pipeline code. No DAG. No orchestrator. One structured document telling an agent what to do, plus a single API call to run it. The runbook is public at mlcroissant.jetty.bot/runbook. The repo is at github.com/jettyio/pdf2croissant.
Run returned “completed” but produced no files.
The runbook was correct. The plumbing was broken. I couldn’t see which until I had the trajectory data showing exactly where the agent stopped. That failure taught me more about writing reliable agent instructions than any blog post about agent reliability ever has.
I’ve written before about runbooks as the missing layer between “call this API” and “accomplish this outcome” — the structured document you’d write for a competent new hire who needs to run your pipeline while you’re on vacation. This is what that looks like when you actually build something with one, failures included.
353 lines was not enough
The first version ran to 353 lines. The agent would read the paper, sometimes generate valid JSON-LD, and declare victory. One output file out of three. Sometimes zero. Status: completed.

Iteration 1: I added a verification script. After generating the Croissant file, the agent runs bash that checks: does the file exist? Is it valid JSON? Does it schema-validate? Each check prints PASS or FAIL.
The agent would check its work, see FAIL printed right there, and declare success anyway.
Iteration 2 felt undignified but worked. I added aggressive mandate language: “MANDATORY — do not skip. You MUST produce all output files. No exceptions.” This sounds like yelling at a computer. Mechanically, though, it’s not about tone — it’s about probability mass. Agents sample from a distribution of reasonable next actions. Stronger language shifts the distribution. “Declare victory despite the FAIL line” becomes less probable; “fix the problem” becomes more probable.
Iteration 3: converted prose parameter descriptions to structured tables. The first version had a paragraph describing what a Croissant file should contain. The agent would fill in what it could find and stop when the description got vague. The table version listed every field explicitly. No ambiguity left to exploit.
Here’s an example output from the runbook transforming CoralVQA into Croissant. The task didn’t get harder, instead the instructions got more precise.
The meta-loop
After enough runs to see failure patterns, I started using Jetty’s /optimize-runbook command to accelerate the cycle.
/optimize-runbook reads execution trajectories from previous runs and proposes targeted changes to the runbook — not abstract suggestions but specific findings: “4 out of 7 runs failed at schema validation because the agent omitted containedIn on FileSet objects. Add it to the Common Fixes table.” Or: “There’s a nested shell quoting bug in the verification script. The agent’s jq call fails when the dataset name contains a comma.”
Instead of noodling through logs for thirty minutes, the skill found it in trajectory data in seconds.
What struck me is that this loop is structurally identical to what the runbook asks the agent to do: run, evaluate against criteria, identify the weakest point, make targeted fixes, run again. The difference is just which landscape you’re on. The agent is hill-climbing the output quality. I’m hill-climbing the instructions.
Same algorithm, one level up.
The responsible AI angle
Here’s why I think this matters beyond the exercise of building a web app with a markdown backend.
Most ML datasets ship with a PDF and maybe a HuggingFace card. Human-readable. Not machine-readable. If you want to audit what a model was trained on — provenance, licensing, known limitations, bias documentation — and the answer lives in hundreds of PDFs in different formats, you can’t do that audit at scale. You can gesture at it.
The EU AI Act requires documentation of training data for high-risk AI systems. The NIST AI RMF points in the same direction. Structured dataset documentation is becoming a compliance requirement, not just good practice. Croissant is the format that makes that compliance automatable rather than a documentation project someone has to own and maintain by hand.
The gap is real. Tens of thousands of dataset papers. Almost none of them have Croissant files. The research exists; the structured representation of it mostly doesn’t. As I’ve argued in my post on CI for AI, the infrastructure for treating AI systems rigorously has to exist before you can use it — and machine-readable dataset metadata is about as foundational as it gets.
The scale question
Now I’m wondering how we can efficiently process entire conference proceedings; 3,000+ academic papers and datasets become a single data point for structured question answering. That’s the next experiment I’m thinking about.The Model Arbitrage Opportunity
The final, and perhaps most valuable, angle to this approach is model arbitrage. By defining the agent’s task in a highly structured, portable runbook (a markdown file, in this case), we decouple the instruction from the specific agent or model that executes it.
The RUNBOOK.md becomes the singular, high-quality asset. I used a capable, often more expensive model to write and optimize the runbook—leveraging its superior reasoning to find failure patterns and refine the instructions over dozens of runs. This is the high-cost, high-value authoring phase.
Once the runbook is reliable, as our 442-line version is, the execution cost plummets. The refined runbook can be tested, evaluated, and executed by a smaller, cheaper, and faster model or agent that can simply follow the explicit, crystal-clear instructions. The runbook’s aggressive mandate language, structured tables, and explicit verification steps remove the need for constant high-level reasoning. The expensive model creates the reliable path; the cheaper model walks it.
This enables a clear model arbitrage strategy: pay for peak intelligence once to create the robust instructional layer, and then deploy for a fraction of the cost across thousands of execution runs, achieving reliability without the continuous expense of a top-tier model. It turns the runbook into a universal instruction set, allowing us to swap the underlying agent—the model—as new, cheaper, or more specialized options become available.