
How LLM Judges Make AI Stop Looking Generic
How a scoring rubric replaced eyeballing for brand consistency

I needed brand-consistent illustrations. Not stock photos. Not whatever Midjourney feels like on a given day. Images that match a specific style guide: navy-and-cream linocut prints, or flat vector pelicans on dark blue. Visual consistency that makes a brand feel intentional.
The problem is obvious to anyone who’s tried. Without guardrails, every generation is a roll of the dice. One image comes back photorealistic. The next is cartoonish. A third nails the palette but the composition is wrong. You’re eyeballing each one, and eyeballing doesn’t scale. Worse, it doesn’t transfer. The person who finally cracked the right prompt for last week’s image isn’t around when someone else needs one this week.
This is the “prompt wizard” problem that every organization using generative AI runs into eventually. Someone develops an intuition for how to coax the right output from a model. That knowledge lives in their head. They become the spell-caster, and the rest of the team waits in line. It’s artisanal in the worst sense: unrepeatable, unverifiable, and fragile.
So I built a two-step workflow: generate an image, then judge it against my brand style guide. The loop takes about 30 seconds. Three iterations took me from 2/10 to 9/10. More importantly, the rubric means anyone can run it.
The setup
Step one: generate an image with Gemini.
Step two: send it to GPT-4o with a scoring rubric that describes my brand.
The rubric:
Rate how well this image matches the Pelican Brand style: minimalist flat vector illustration OR vintage hand-drawn printmaking sardine tin art. Key criteria: (1) limited color palette — navy, white, gold for flat vector OR 1-2 muted colors on cream for linocut, (2) correct style, (3) simple composition with the subject filling the frame, (4) NO photorealism, NO cartoon style, NO busy backgrounds. Score 1-10.
One generation model, one judge model, one rubric. The judge returns a score and an explanation of what’s wrong.
Run 1: the raw prompt (2/10)
I started with the kind of prompt you’d write for any image generator:
“A close-up of a magnifying glass held over a printed illustration. Through the lens, the image appears sharper and more defined. Warm studio lighting, shallow depth of field.”
The result looked like this:

Technically impressive. Completely off-brand. The judge scored it 2/10: “Photorealistic with complex shading and depth of field. Does not match either the flat vector or printmaking style.”
I knew this would fail. The point is that the judge articulates why in terms I can act on: too realistic, wrong style, too much detail.
Run 2: adapted to brand style (8.5/10)
I rewrote the prompt using a template I’d developed for the linocut style:
“Bold linocut block print illustration on cream paper. A circular feedback loop with four stations: a pencil, a picture frame, a magnifying glass, and a gauge. Thick arrows connect them in a cycle. Hand-carved woodcut style, imperfect ink edges, heavy line weight. Single color dark navy blue ink on cream paper. No text. Vintage printmaking aesthetic.”
Same concept. Completely different constraints:
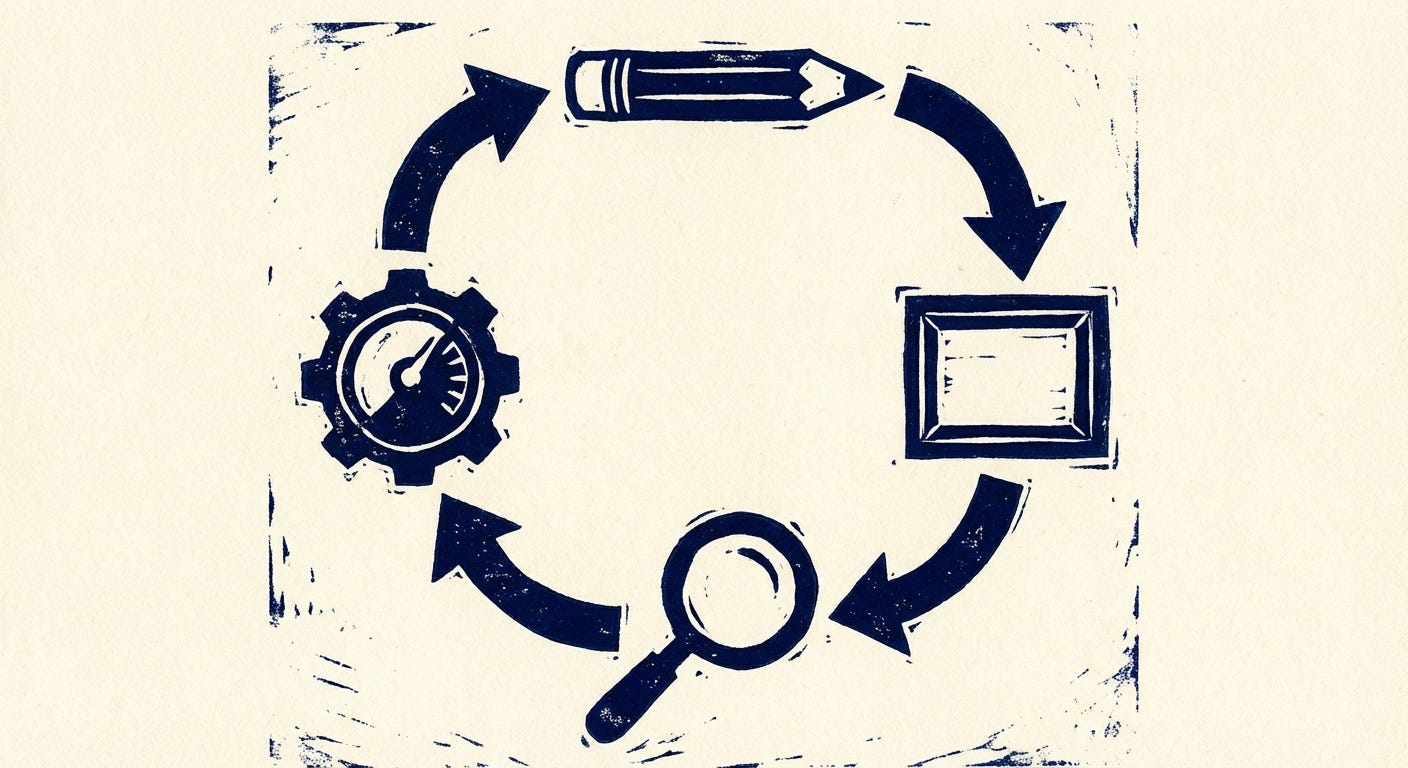
The judge scored it 8.5/10: “Closely matches the vintage hand-drawn printmaking style. Limited color palette with navy on cream. Simple composition with the subject filling the frame.”
From 2 to 8.5 in one rewrite.
Run 3: refined from feedback (9/10)
The judge’s only complaint: composition could be tighter. I added “subject enclosed in a single bold circle, tightly cropped” and strengthened the ink texture language:
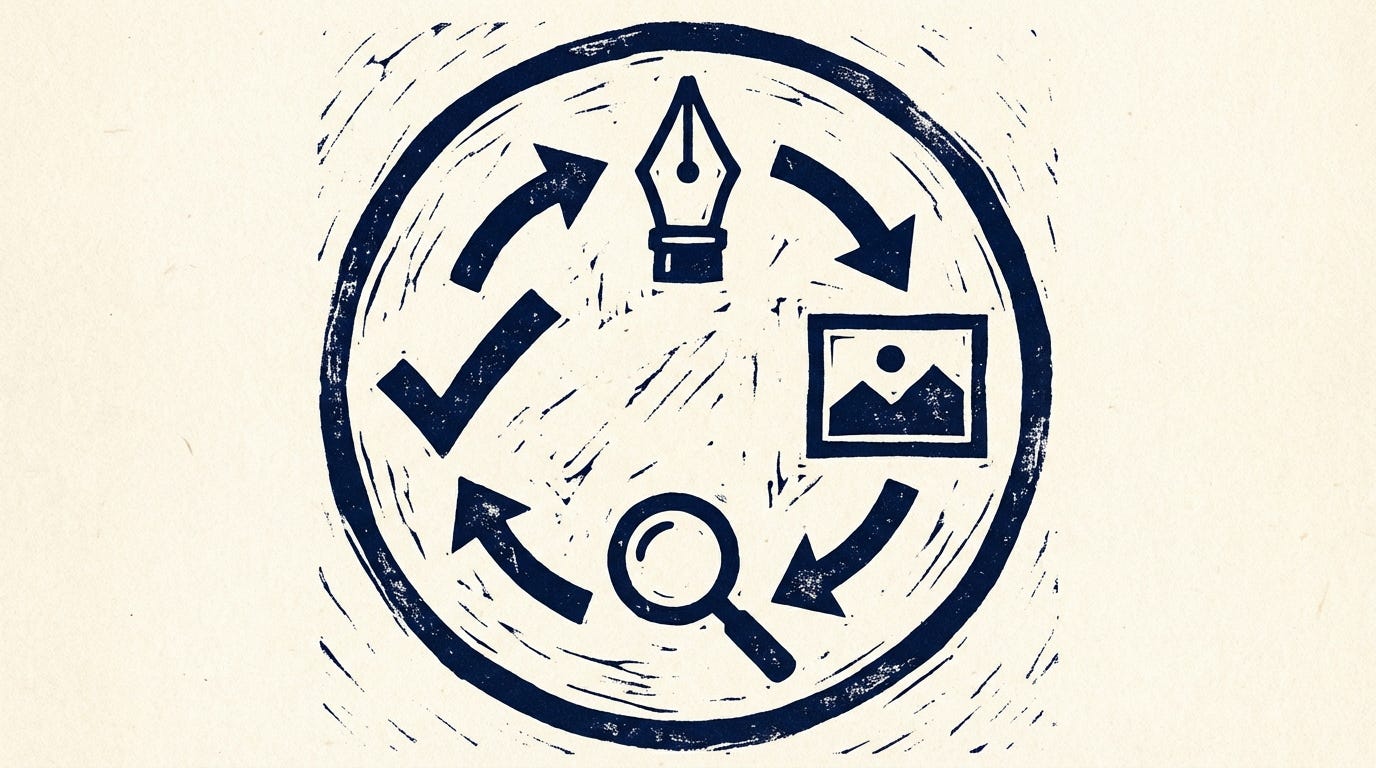
Score: 9/10. Three runs. Five minutes of prompt editing. The judge did the hard work of evaluating consistency.
Without the judge vs. with it
To make the difference concrete, I ran five short nautical prompts through both pipelines. Same concepts, same image model. The only difference: one has the brand judge, one doesn’t.
Without the judge — five 3-word prompts, no guardrails:
Anchor in rough seas:


Lighthouse at night:


Ship in a bottle:


Sailor tying a knot:


Five prompts, five completely different visual styles. Photorealism, nature photography, portraiture, still life.
The prompt templates do the heavy lifting. Once I dialed them in with the judge’s feedback, producing a new on-brand image is a one-liner: swap in the concept, run the pipeline. No wizardry required.
The pattern
This isn’t really about images. It’s the same loop I keep running into with AI systems: close the gap between generation and evaluation.
Generate with whatever model you want
Judge against a written rubric using a different model
Read the feedback and adjust
Repeat until the score converges
The architecture is two API calls and a scoring prompt. You could wire this up with a script, but the reason I built it as a Jetty pipeline is that the same workflow runs for every image, every time, without someone babysitting it. Define the rubric once, and anyone on the team can generate on-brand images without becoming a prompt expert. The insight is that LLM-as-judge works for images, not just text. A written rubric can encode brand guidelines well enough to automate taste.
This is what kills the spell-caster problem. The wizard’s intuition about “what works” gets externalized into a rubric that anyone can run. No one needs to know which magic words make Gemini produce a good linocut. The judge tells you what’s wrong, and the fix is usually obvious from the feedback. The taste lives in the rubric, not in someone’s head.
Every image I generate without this loop is a coin flip that either reinforces my brand or dilutes it. With the loop, the images converge. After a few rounds, you develop reusable prompt templates that score 8+ on the first try.
Try it
The whole pipeline is one workflow definition and a rubric. I built it by asking Jetty’s CLI to create a two-step pipeline: generate an image, then judge it. That’s it. The rubric is a text file. The prompt templates are text files. Once you have a look and feel that works, every new image is a one-line prompt with the concept swapped in.
If you want to adjust the judge, you don’t need to touch code. Update the rubric text and run it again. I’ve tweaked the scoring criteria three times since I started, each time just by editing what “on brand” means in plain English.
Fork the repo, swap in your own style guide, and run it. The loop works for any brand style, not just mine. Write a rubric that describes what “on brand” means for you. Be specific: name the colors, the style, what to avoid. The judge will tell you what’s wrong faster and more consistently than you can eyeball it.
If your brand images look different every time, the problem isn’t the image model. It’s the absence of a feedback loop.