
Generation Got Cheap. Verification Didn't.
Cheaper tokens don't mean cheaper AI systems

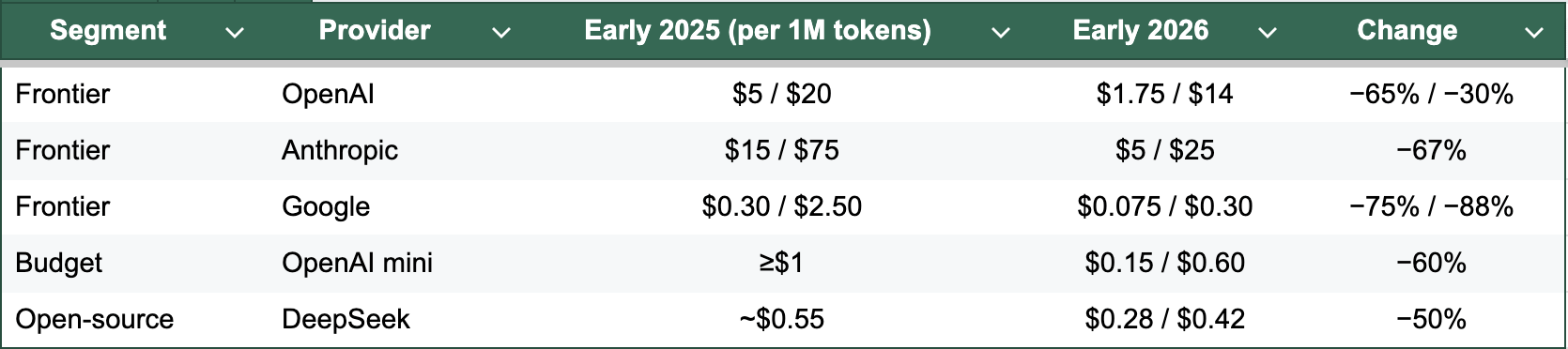
Last spring, shipping with GPT-4o meant budgeting $5 per million input tokens. Enterprise teams paying for Claude Opus were spending $15 input, $75 output. Twelve months later, GPT-5.2 sells for $1.75 input. Anthropic slashed Opus by 67%. Google’s Flash-Lite is down to $0.075 per million tokens. DeepSeek cut prices by half and now lists $0.28 input.
The MTok crash is real. Across every weight class, generation costs fell 30–80% in a year.
But it misses the harder question. If generating output is approaching commodity pricing, what’s still expensive?
The cost nobody talks about
A team I work with runs a support chatbot. Last year it cost them about ±$18,000 a month on GPT-4o. When GPT-5.2 dropped at a third of the price, they migrated. The inference bill fell to roughly $6,000.
What didn’t change: the three engineers who review escalated cases. The QA process that spot-checks 2% of responses. The weekly meeting where someone eyeballs a dashboard and says “looks fine.” The verification layer stayed exactly the same size while the output tripled.
They didn’t save $12,000. They took $12,000 worth of increased risk.
This is happening everywhere. A recent paper from MIT formalizes what practitioners already feel. Christian Catalini, Xiang Hui, and Jane Wu model the AI transition as a collision between two cost curves:
The cost to generate (what they call c_A) is driven by compute and accumulated knowledge. As both scale, the cost drops exponentially. That’s the MTok crash in the table above.
The cost to verify (c_H) is driven by human time, feedback latency, and expertise. It’s bounded by biology. An experienced engineer can review traces faster than a junior one, but experienced engineers are scarce, and their wages rise with scarcity. The paper calls this “verification cost disease”: even when experts get more efficient, verification gets more expensive because the demand for their judgment grows faster than the supply.
These curves are diverging. Generation costs collapse. Verification costs stay flat or rise. The gap between them is widening.
The gap has a name
Catalini et al. call it the Measurability Gap: the growing share of tasks where machines can cheaply generate output that humans cannot affordably verify. Their argument is that this gap, not the price of tokens, is the binding constraint on productive AI deployment.
Think about it in terms of your own system. Cheap tokens don’t just save money. They change what’s economically viable to automate. When GPT-4o cost $5 per million input tokens, teams were selective about which tasks they automated. They routed FAQ queries to the model and left complex cases to humans. The generation cost acted as a natural filter.
At $1.75 per million tokens, the filter dissolves. Teams start routing everything through the model. Not just FAQs but nuanced customer complaints, refund decisions, edge cases that used to get flagged for review. Each individual decision is defensible: the model handles it well enough, and it’s so cheap there’s no cost argument against it.
But “handles it well enough” is an impression, not a measurement. Nobody increased the verification budget to match the expanded scope. The team still reviews the same 2% sample. The same three engineers attend the same weekly meeting. And the fraction of output that’s actually verified shrinks with every new task the model picks up.
The paper formalizes this as four zones:
Safe Industrial. Cheap to automate, cheap to verify. This is where AI success stories live. Chatbots answering FAQs. Classification tasks with clear ground truth. Code formatting. The output is easy to check, so automation works.
Runaway Risk. Cheap to automate, expensive to verify. This is the zone that expands as token costs crash. The model can generate the output, but proving it’s correct requires human expertise that doesn’t scale with compute. Legal summaries. Medical triage suggestions. Financial recommendations. Content moderation at volume.
Human Artisan. Expensive to automate, cheap to verify. Humans still do it better, and you can tell when they do. This zone is shrinking as models improve, but it’s where craftspeople live today.
Pure Tacit. Expensive to automate, expensive to verify. Strategy. Judgment under uncertainty. The work that’s hard to even define, let alone evaluate.
The Runaway Risk zone is the one that should worry you. Every time a model gets cheaper, more tasks cross the automation threshold. But the verification threshold doesn’t move. The zone grows.
What happens in the gap
I’ve watched this play out in specific ways.
A marketing team I know went from producing 50 assets per campaign to over 4,000. Same team size. Same approval process, in theory. Three people can’t review 4,000 assets. They spot-checked, trusted the prompts, and shipped. When an off-brand image made it into a campaign, nobody could trace it back to the generation run that produced it.
That’s the Runaway Risk zone in action. Generation cost dropped to near zero. Verification didn’t scale to match.
Or take model swaps, the most common optimization move. A new model is cheaper. It scores higher on benchmarks. An engineer tests it against a handful of examples, everything looks good, they ship it. Three weeks later a support ticket arrives for a failure mode the old model handled correctly. Nobody connects the ticket to the swap because it doesn’t look like a regression. It looks like a new bug.
I wrote about this pattern in an earlier piece. Teams optimize individual steps without measuring the whole system. Each change is defensible in isolation. In aggregate, the system isn’t meaningfully different from where it started. Cheaper tokens accelerate this cycle. More model options, more swaps, more lateral moves disguised as progress.
The Catalini paper has a blunt name for unverified output: a “Trojan Horse” externality. It looks like productive work. It satisfies the metrics you’re tracking. But it accumulates hidden risk in the gap between what you can measure and what you can’t.
Where the savings should go
Here’s the math most teams don’t do.
That support bot dropped from $18,000 to $6,000 a month. The $12,000 savings is real. The question is where it goes. Most teams take it as margin. Finance is happy. The line item went down.
But the team also expanded the bot’s scope. It handles 3x more query types. The generation budget decreased while the verification burden increased. If none of that $12,000 flows into evaluation infrastructure, the team hasn’t saved money. They’ve converted an explicit cost (tokens) into an implicit one (undetected failures).

What does reinvesting look like in practice?
Eval suites on production traces. Not the handful of test cases assembled six months ago. Evaluation sets built from what the system actually encounters, refreshed continuously, covering the edge cases that model swaps introduce. If your eval set hasn’t changed since the last model migration, it’s lying to you.
LLM judges for tasks humans can’t review at volume. A second model scoring the first against a written rubric. Does this response match our tone? Did the summary preserve the key facts? Is this classification consistent with how we’ve handled similar cases? Judges don’t replace human review, but they extend it. They catch the mechanical failures before a human ever has to look.
Automated pipelines that flag regressions before users do. The loop I keep coming back to: ingest traces from production, run evaluations against them, surface the findings as concrete changes an engineer can review. Not a dashboard. A diff. Something that lives in the workflow you already have.
This is the work we do at Jetty. We ingest traces from observability platforms, run evals, and produce pull requests with verified improvements. The MTok crash makes this more urgent, not less. When generation was expensive, the verification gap was narrow. Teams automated selectively and could review what they shipped. As generation approaches commodity pricing, the gap widens. The teams that invest in closing it will capture the surplus from every price cut. The teams that don’t will race to the bottom on inference costs and wonder why their systems aren’t getting better.
The question worth asking
The MTok crash didn’t make AI cheap. It made generation cheap. Those are different things.
Verification is the new scarce input. The ability to prove your system is working, to catch regressions when you swap models, to evaluate at the scale of your output rather than the scale of your team. That’s what’s still expensive. And unlike tokens, it doesn’t get cheaper by waiting for the next model release.
Every team I talk to has a version of the same plan: “We’ll optimize our AI stack once we have time.” The MTok crash gives them the budget. But budget without verification infrastructure is just faster generation of output nobody’s checking.
The question isn’t “which model should we use now that everything’s cheaper?” It’s “do we have any way to know if our system is working at the scale we’re running it?”
If the answer is no, cheaper tokens just means you’ll be wrong faster.